Planet Batch & Slack Pipeline CLI¶
![]()
![]()
![]()
 © Planet Labs(Full line up of Satellites) and Planet & Slack Technologies
Logo
© Planet Labs(Full line up of Satellites) and Planet & Slack Technologies
Logo
For writing a readme file this time I have adapted a shared piece written for the medium article. The first part which is setting up the slack account, creating an application and a slack bot has been discussed in the article here. In the past I have written tools which act as pipelines for you to process single areas of interest at the time that could be chained, the need to write something that does a bit more heavy lifting arose. This command line interface(CLI) application was created to handle groups and teams that have multiple areas of interest and multiple input and output buckets and locations to function smoothly. I have integrated this to slack so you can be on the move while this task can be on a scheduler and update you when finished.
Table of contents¶
- Installation
- Getting started
- Batch Approach to Structured JSON
- Batch Activation
- Batch Download and Balance
- Additional Tools
- Citation and Credits
- Changelog
Installation¶
The next step we will setup the Planet-Batch-Slack-Pipeline-CLI and integrate our previously built slack app for notifications. To setup the prerequisites you need to install the Planet Python API Client and Slack Python API Clients. * To install the tool you can go to the GitHub page at Planet-Batch-Slack-Pipeline-CLI. As always two of my favorite operating systems are Windows and Linux, and to install on Linux
git clone https://github.com/samapriya/Planet-Batch-Slack-Pipeline-CLI.git
cd Planet-Batch-Slack-Pipeline-CLI && sudo python setup.py install
pip install -r requirements.txt
- for windows download the zip and after extraction go to the folder containing "setup.py" and open command prompt at that location and type
python setup.py install pip install -r requirements.txt
Now call the tool for the first time, by typing in pbatch -h. This will only work if you have python in the system path which you can test for opening up terminal or command prompt and typing python.
Getting started¶
Once the requirements have been satisfied the first thing we would setup would be the OAuth Keys we created. The tools consists of a bunch of slack tools as well including capability to just use this tool to send slack messages, attachments and clean up channel as needed.
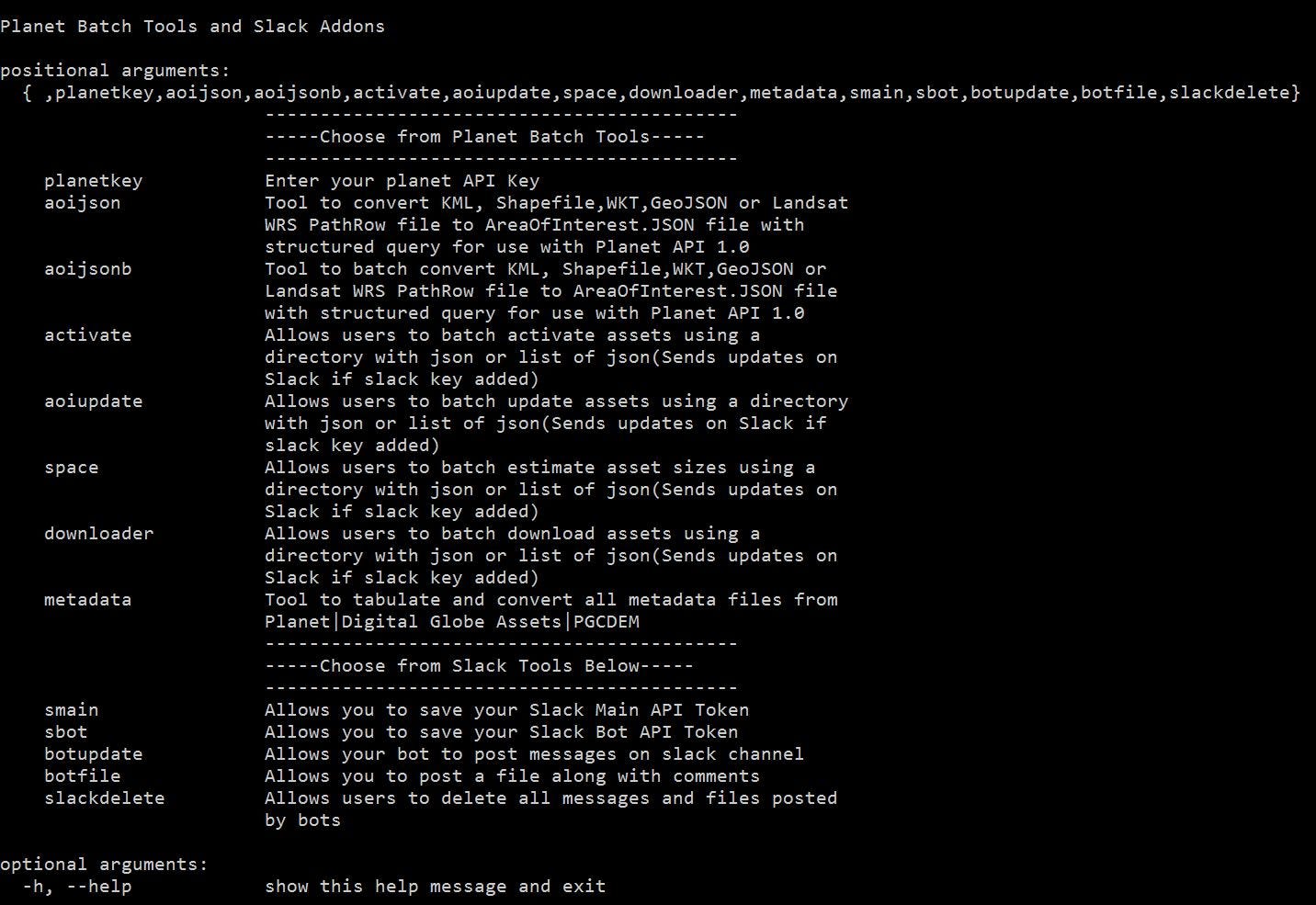 Planet Batch Tools and Slack Addons Interface
Planet Batch Tools and Slack Addons Interface
The two critical setup tools to make Slack ready and integrated are the smain and sbot tools where you will enter the OAuth for the application and OAuth for the bot that you generated earlier. These are then stored into your session for future use, you can call them using
pbatch smainUse the "OAuth Access Token" generated earlier. You can find the tutorial here
If you want more control over being able to delete slack messages you would
want to generate a token here and use that as the **pbatch smain** token.
pbatch sbotUse "_Bot User OAuth Access Token" _generated earlier. You can find the tutorial here
Once this is done your bot is now setup to message you when a task is completed. In our case these are tied into individual tools within the batch toolkit we just installed.
In case you ever forget your API keys or need it again you can access all installed applications/bots and oauth tokens here.
To be clear these tools were designed based on what I thought was an effective way of looking at data, downloading them and chaining the processes together. They are still a set of individual tools to make sure that one operation is independent of the other and does not break in case of a problem. So a non-monolithic design in some sense to make sure the pieces work. We will go through each of them in the order of use pbatch planetkey is the obvious one which is your planet API key and will
allow you to store this locally to a session.
The _aoijson tool is the same tool used in the Planet-EE CLI within the pbatch bundle allows you to bring any existing KML, Zipped Shapefile, GeoJSON, WKT or even Landsat Tiles to a structured geojson file, this is so that the Planet API can read the structured geojson which has additional filters such as cloud cover and range of dates. The tool can then allow you to convert the geojson file to include filters to be used with the Planet Data API._
Let us say we want to convert this map.geojson to a structured aoi.json from June 1 2017 to June 30th 2017 with 15% cloud cover as our maximum. We would pass the following command
pbatch.py aoijson --start "2017-06-01" --end "2017-06-30" --cloud "0.15" --inputfile "GJSON" --geo "local path to map.geojson file" --loc "path where aoi.json output file will be created"
Batch Approach to Structured JSON¶
This tool was then rewritten and included in the application to overcome two issues 1) Automatically detect the type of input file I am passing (For now it can automatically handle geojson, kml, shapefile and wkt files). The files are then saved in an output directory with the **filename_aoi.json . **
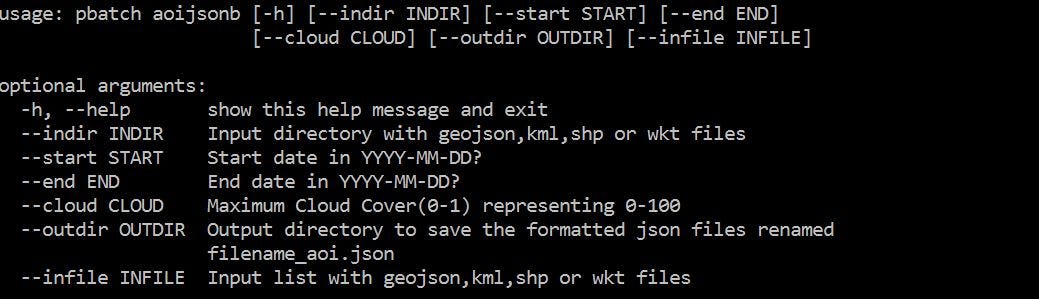
The tool can also read from a csv file and parse different start dates, end dates and cloud cover for different files and create structured jsons to multiple locations making an multi path export easy. The csv headers should be The csv file needs to have following headers and setup
| pathways | start | end | cloud | outdir |
|---|---|---|---|---|
| C:\demo\dallas.geojson | 2017-01-01 | 2017-01-02 | 0.15 | C:\demo |
| C:\demo\denver.geojson | 2017-01-01 | 2017-03-02 | 0.15 | C:\demo |
| C:\demo\sfo.geojson | 2017-01-01 | 2017-05-02 | 0.15 | C:\demo |
| C:\demo\indy.geojson | 2017-01-01 | 2017-09-02 | 0.15 | C:\demo |
Below is a folder based batch execution to convert multiple geojson files to structured json files

Batch Activation¶
This tool was rewritten to provide users with two options to activate their assets. They can either point the tool at a folder and select the item and asset combination or they can specify a CSV file which contains each asset and item type and path to the structured JSON file. A setup would be as simple as
pbatch activate --indir "path to folder with structured json files" --asset "item asset type example: PSOrthoTile analytic"
The csv file need to have headers
| pathways | asset |
|---|---|
| C:\demo\dallas_aoi.json | PSOrthoTile analytic |
| C:\demo\denver_aoi.json | REOrthoTile analytic |
| C:\demo\sfo_aoi.json | PSScene4Band analytic |
| C:\demo\indy_aoi.json | PSScene4Band analytic_sr |
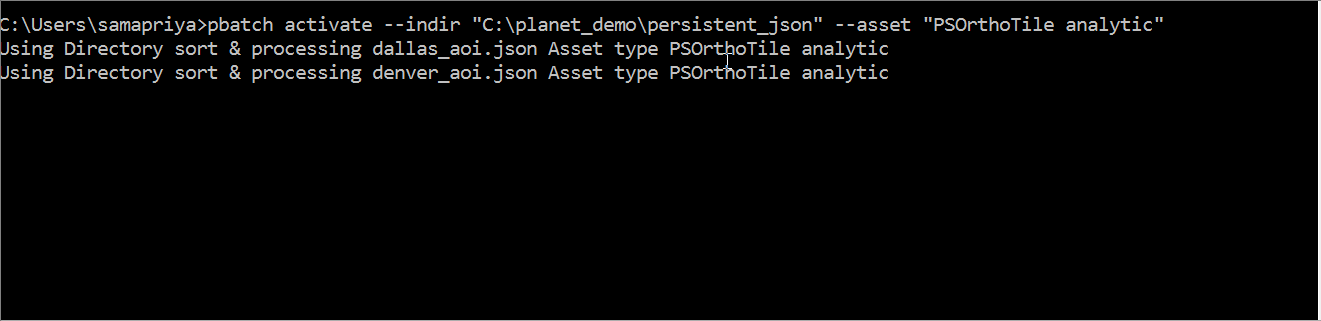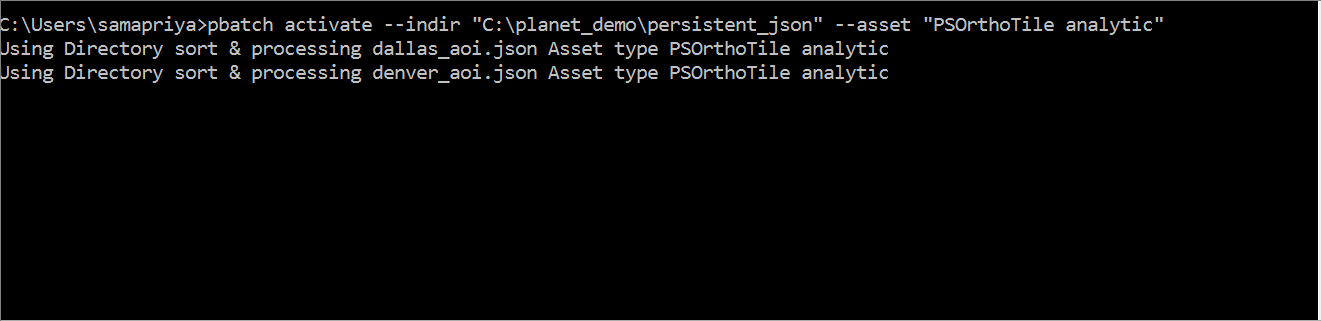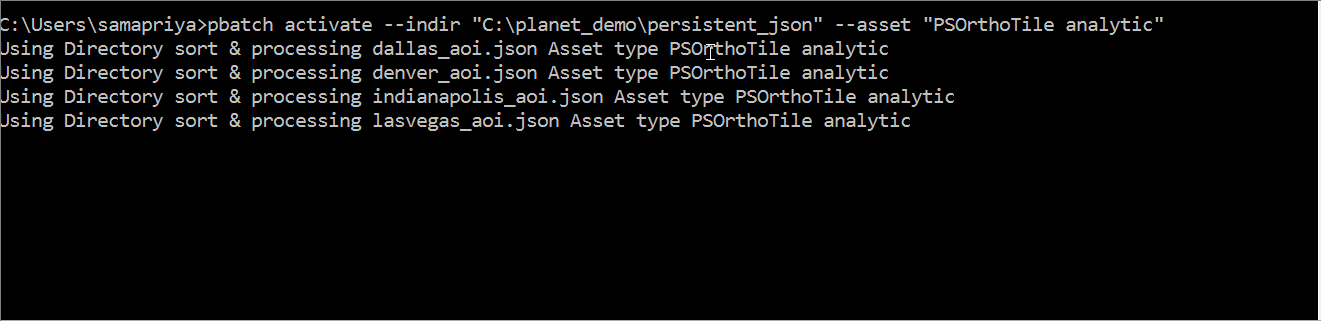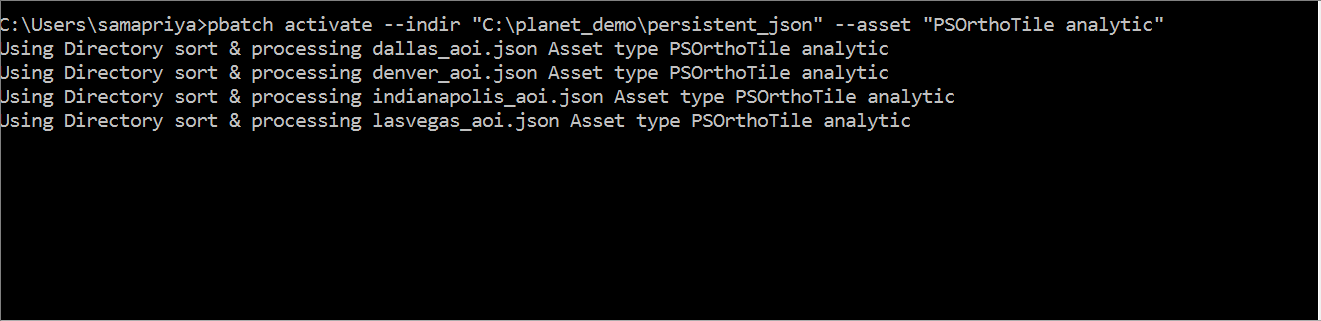
The tool generates a slack readout which includes the filename , the asset and item type and the number of item and asset combinations that have been requested for activation
Batch Download and Balance¶
We run the downloader tool to batch download these assets and again you can choose to have either a folder or a csv file containing path to the json files, the item asset combination and the output location. A simple setup is thus
pbatch downloader --indir "Pathway to your json file" --asset "PSOrthoTile analytic" --outdir "C:\output-folder"
The csv file needs to have following headers and setup
| pathways | directory | asset |
|---|---|---|
| C:\demo\dallas_aoi.json | C:\demo\t1 | PSOrthoTile analytic |
| C:\demo\denver_aoi.json | C:\demo\t1 | REOrthoTile analytic |
| C:\demo\sfo_aoi.json | C:\demo\t1 | PSOrthoTile analytic_xml |
| C:\demo\indy_aoi.json | C:\demo\t1 | REOrthoTile analytic_xml |
 Batch downloading
using folder
Batch downloading
using folder
This tool is unique for a few reasons
- This can using the CSV sort to identify different pathways to strctured jsons in different locations, but it can also download different assets for each input file and write to different location each time. Meaning this can be of production value to teams who have different source folders and output buckets where they would want their data to be written.
- The tool also prints information of Number of assets already active, number of assets that could not be activated and the total number of assets. Incase number of assets active do not match those that can be activated it will wait and show you a progressbar before trying again. This is the load balancing for each input file while making sure you don't have to estimate wait times for large requests.
The tool generates a slack message posted on your channel letting you keep track of downloads.
Additional Tools¶
Two things that keep changing are space (The amount of space needed to store your data) and the time since you may want to look at different time windows . With this in mind an easy way to update you about the total space for the assets you activated I created a tool called pbatch space . A simple setup would be
pbatch space --indir "Input directory with structured json file" --asset "PSOrthoTile analytic"
And it can also consume a csv file where the csv file need to have headers
CSV Setup to estimate size of assets in GB
| pathways | asset |
|---|---|
| C:\demo\dallas_aoi.json | PSOrthoTile analytic |
| C:\demo\denver_aoi.json | REOrthoTile analytic |
| C:\demo\sfo_aoi.json | PSScene4Band analytic |
| C:\demo\indy_aoi.json | PSScene4Band analytic_sr |
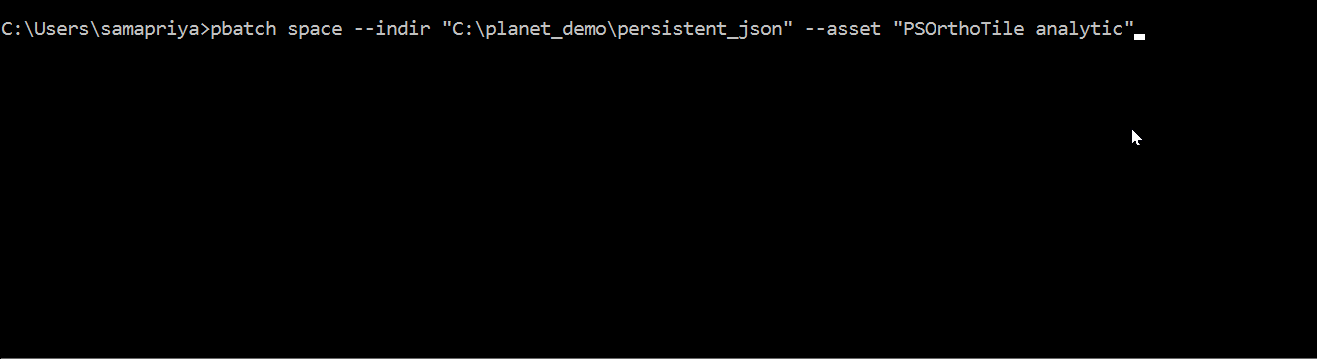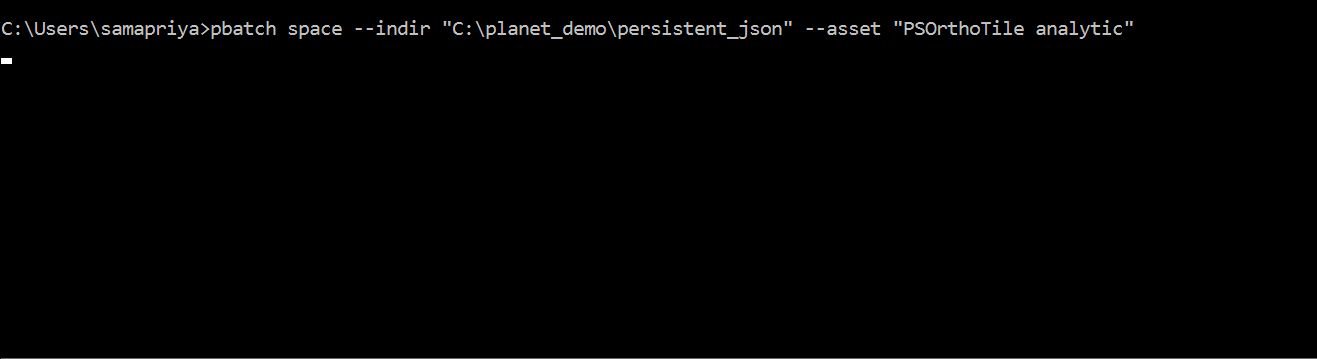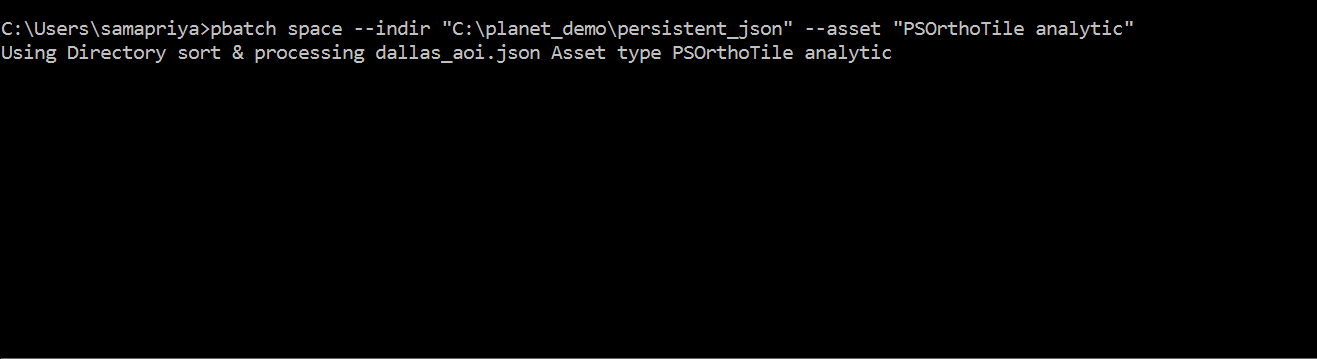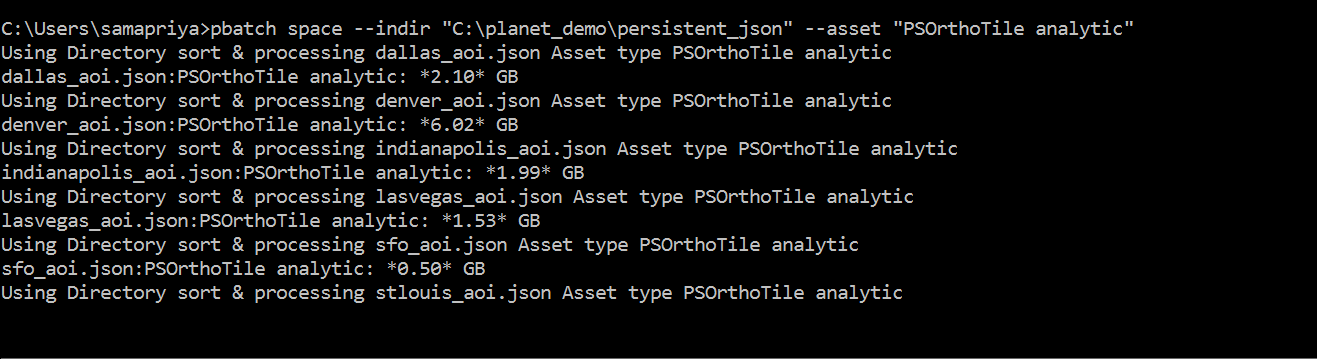
Slack will record the last time you ran this tool because new assets may have activated since you last ran this or new assets may have become available for you to activate. This tool is useful only after you have activated your assets.
To quickly change start times on structured JSON I created another tool pbatch aoiupdate. Most often all your data needs can be considered as x number of days from whatever you sent . Meaning I may want to look at 30 days of data from the end date and we don't want to recreate the structured json files. Turns out we can easily change that using a time delta function and simply rewrite the start date for our json files from which to start looking
for data.
Note: Your end date should be current date or later the way the date is now written is date greater than equal to 30 days from today and end date remains constant

A good rule of them to be safe with this tool is to save the end date into the future so for example. The setup maybe
pbatch aoiupdate --indir "directory" --days 30
start date "**2017-01-01**" end date "**2017-12-31**"
new start date "**2017-10-26**" new end date "**2017-12-31**"
You can also create a CSV setup for this as well with different days for each JSON file
CSV Setup to update structured JSON. Note: the number of days is calculated from current date
| pathways | days |
|---|---|
| C:\demo\dallas_aoi.json | 3 |
| C:\demo\denver_aoi.json | 5 |
| C:\demo\sfo_aoi.json | 14 |
| C:\demo\indy_aoi.json | 23 |
Another tool that was solely written witht he purpose of integration with Google Earth Engine is the pbatch metadata which allows you to tabulate metadata and this is for use in conjunction with Google Earth Engine atleast for my workflow.
Citation and Credits¶
You can cite the tool as
- Samapriya Roy. (2017, December 4). samapriya/Planet-Batch-Slack-Pipeline-CLI: Planet-Batch-Slack-Pipeline-CLI (Version 0.1.4). Zenodo. http://doi.org/10.5281/zenodo.1079887
Thanks to the Planet Ambassador Program
Changelog¶
v0.1.4¶
- Now handles CSV formatting for all tools
- Added CSV Example setups folder for use
v0.1.3 (Pre-release)¶
- Handles issues with subprocess module and long wait
v0.1.2 (Pre-release)¶
- Updates to parsing CSV, optimized handling of filetypes
v0.1.1 (Pre-release)¶
- Updates to Batch download handler